

《MultiWOZ 2.2 : A Dialogue Dataset with Additional Annotation Corrections and State Tracking Baselines》
这篇论文发布了MultiWOZ数据集的升级版
作者来自谷歌和伊利诺伊大学芝加哥分校
MultiWOZ发展史
先介绍一下MultiWOZ的发展史。
1. New WOZ (multi-domain)
首先,在18年,剑桥大学的研究人员在提出了一个新的multi-domain dst模型的同时,顺带着提出了一个新的数据集。在论文里叫做New WOZ(multi-domain)。发表在ACL。
Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing
2. MultiWOZ 2.0
之后,剑桥大学的这群研究人员又单独发了一篇论文,提出了MultiWOZ这个数据集。也是当年emnlp的best paper。
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
3. MultiWOZ 2.1
在19年,亚马逊的研究人员针对2.0中的一些错误做了修正,添加了对槽位的解释和对对话行为的标注。新的数据集叫做MultiWOZ 2.1。发表在LREC2020。
4. MultiWOZ 2.2
今年,谷歌的学者提出了2.1的升级版2.2。
标注错误
下面来介绍一下2.2对2.1的改进,首先是标注错误。
在介绍标注错误之前,我们先来了解一下什么是Wizard-of-Oz setup。
Wizard-of-Oz setup是由两个众包工人组成一队,一个扮演user,一个扮演agent。
每组对话由一个特定的目标来驱动。
在每轮user对话结束后,扮演agent的众包工会标注出更新后的对话状态,并依此生成一个回复。
由于这种方式是完全靠人工去标注的,那么就会容易产生噪声。
Hallucinated Values
作者将标注中错误的value叫做分为4类。
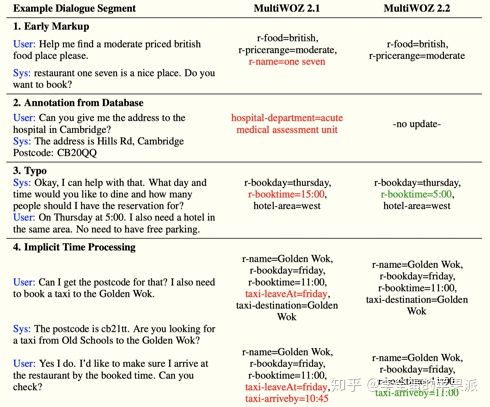
1. early markup
这类未来会出现的槽值被agent标注成了当前的值。
2. Annotations from Database
这些值压根就没有在对话中出现,而是被程序错误的从数据库中抽取出来的。
3. Typos
一些印刷或者排版错误。
4. Implicit Time Processing
一些隐式的时间表示,他有可能是根据前面的相对时间加减计算出来的时间,也有时候回四舍五入到最接近的时间。这样会加重模型学习的负担。
状态更新不一致
状态更新不一致的主要原因有两种:
1. value来源有多个
一个槽值在对话状态可能有各种来源:由用户提出、由系统提供、从对话状态中不同的domain下的值继承过来的、来源于本体中定义的。
2. value的释义不规范
多个value其实含义是一样的。2.1在定义这些内容的时候缺乏一个显式的规则。这就使得模型训练的时候造成困惑,比如说同时有18:00和6pm,其实都是对的,但是训练过程中由于ground truth只有一个,那么就会错误的penalize另一个value。

3. 跟踪策略不一致
众包工人标注时的标准不一致,有的只标除了用户提到的value,有的将用户同意的agent提到的value也标了进来。

本体中的问题
在multi woz 2.0中定义了一个本体,他声称枚举了所有slot的所有value。但是后来的研究人员发现这个本体其实是很不完整的,以致于为了达到跟好的效果,研究人员往往要自己再重新定义一个自己的本体。为了解决这个问题,2.1试图列出对话状态中的所有值来重建本体,但是仍然存在一些未解决的问题。
就比如说
1.在同一槽位中,具有相同语义的多个value
2.本体中多个slot-value无法与数据库中的实体相关联
靠字符串匹配,21%的slot-value无法在数据库中找到对应
作者认为,本体应该要么完全省略这样的表达,要么包括所有可能的表达,以能够泛化到训练数据中未观察到的情况。
纠正程序
为了解决上面提到了这些问题,作者这里提到了一套纠正程序。
首先,关于本体。在本体中为slot枚举所有可能的value是一件很不现实的事情。比如说餐馆的名称,订餐的时间。
因此,这里沿用了本文的二作之前一篇工作上的内容,叫做schema。
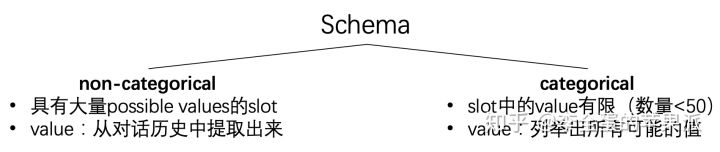
schema将所有slot分成两类,一类叫做non-categorical,一类叫做categorical。
non-categorical包括那些具有大量可能的value的slot,schema中对这些slot不去预定义一个value的list,对于这类slot的value是从对话历史中提取出来的。
categorical包含了那些value有限的slot,以及在训练数据中具体value数量少于50个的slot。在schema里头对这类slot会列举出所有可能的value。
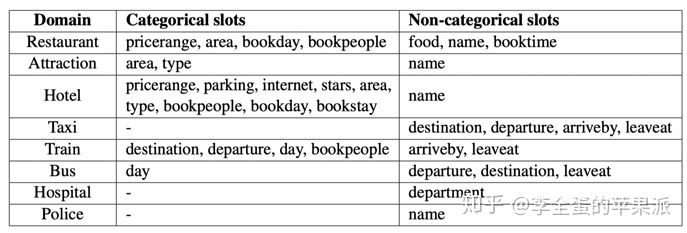
Categorical Slots
对于分类槽位,所有可能的值都是由2.1的数据库构建的。
其中有两个特殊的词,dont-care和unknown。
dont-care是在用户对某一个值没有偏好的时候使用的。
unknown指的是那些在schema中的值无法满足用户特定的需求。
例如:

其中$100是hotel-price的槽值,但是数据库中只有cheap、moderate和expensive。因此此处应将槽值标注为unknown。
Non-categorical Slots
对于非分类槽位。上面已经说过,它的value是从对话历史中提取出来的。作者这里用一种字符串匹配的方式找到对话历史中语义最接近的值。如果有多个,就取最近提到的那个。
在2.2中,在标注中允许一个slot有多个value,模型预测出来任意一个都算对。
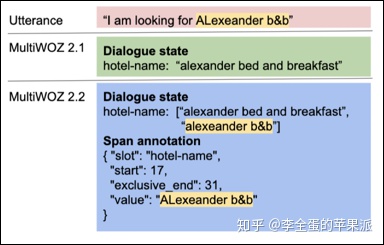
当多个slot对应的是同一个value的时候,作者这里采用链式存储的思想。后来的slot不标注span,而是标注出这个value对应的原始的slot。
作者认为,这种信息对于利用拷贝机制的状态追踪模型是有益的。
User and System Actions
在对话行为方面,2.1中有5.82%的对话轮数没有标注对话行为,一共8333轮,包括7339轮用户的utterance,和994轮系统回复。作者请众包工完成了这些遗漏的对话行为的标注。
此外,在2.1中的对话行为前面都有一个关于当前domain的前缀,作者这里把这些前缀删掉了,以便在所有domain上使用同一的对话行为表示。
那么,为了保持对话行为和domain之间的联系,这里用到了本文二作之前的一个做法,将同一domain下的对话对话行为组合起来放到了frames里。
一些数据
1.从28.2%的对话中,修正了17.3%用户话语的对话状态
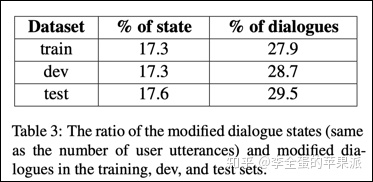
2.修正了12,375条话语的标注(大部分由于对话状态更新不一致)
3.其中有1497(12%)条涉及到两个或多个slot
4.为8,333个话语添加了缺失的对话行为
5.修正了10%话语的对话行为
额外的标注
除了对前人工作的修正,作者这里还做了一些额外的标注工作。
Active intents
active intent指定了用户话语中表达的所有意图。
对于搜索(search)类型的意图,包括了 Attraction, Bus, Hotel, Police
对于订购(book)类型的意图,包括了 Taxi
两种类型的意图都适配的领域包括Restaurant, Hotel, and Train
Requested slots
Requested slots指定了用户想系统请求的槽位,也就是所谓的提问槽。
这个是由每轮的用户行为生成的。
作者认为,这种槽位在任务型对话系统中是很常见的,因此这类标注对于构建对话模型具有直接适用性。
DSTBenchmark
作者基于新的数据集,发布了新的benchmark。
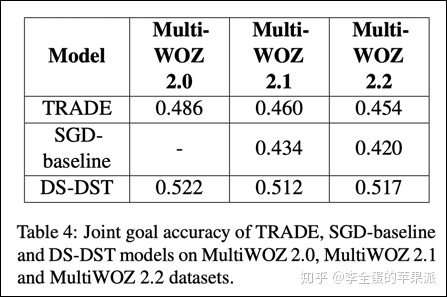
baseline包括:SGDbaseline、TRADE、DS-DST
由于这篇文章将slot分为了categorical和non-categorical两类。因此对于这两类slot应该用两种方法去做。
categorical是在预定义的候选项中做分类。
non-categorical是从对话历史中抽取span。
1. TRADE
对于TRADE,作者这里采用混合抽取的方式,用指针生成器的架构,从候选项或者对话历史中抽取答案。
2. SGDbaseline
对于SGDbaseline,作者是将两种类别的slot分开处理。一个做分类,一个抽span。
3. DS-DST
DS-DST也是与SGD同样的方式。
不同的是,他的对话上下文的embedding是取决于slot-value的信息的(slot-value和上下文一起做embedding)
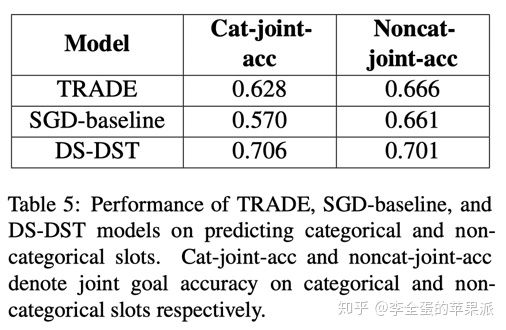
在categorical和non-categorical两类slot上单独计算joint-acc
有上表可以看出,TRADE和SGD在non-categorical上的得分要比categorical更高。
作者推断,这可能是因为前面做的修正,确保了所有non-categorical的value在对话历史中都有出现。
讨论
Wizard-of-Oz范式虽然是个强有力的收集自然语言对话的技术,但是他也存在很大的噪音。作者在这一节就提出了几点,来最小化标注错误。
1.在标注数据前,应该先定义一个本体或者schema。对于categorical的槽位,这个schema需要定义好明确的slot,每个slot都有一个固定的可能的value的集合。然后标注接口,需要强制性的保证这些槽值的正确性。对于non-categorical的槽位,标注接口要限制标注的value必须是出现在对话历史中的值。
2.在标注任务之后,可以进行简单的检查,以识别错误的标注。
设想
最后,作者提出了一个设想。
在2.1中,有一些逻辑表达式标注的value,但数量很少,占总数不到1%。
例如:
1.cheap>moderate
2.cinema|entertainment|museum|theatre
3.cheap>moderate,就表示用户相比moderate,更想要cheap。
用|分隔开的value表示这些value对用户来说都是可以接受的。
但是模型很难处理这种情况。因此,作者在最后提出了两个设想:
1.如何定义一个可以支持这类复杂标注,且更具有表现力的表现形式
2.如何设计一个有能力处理这类问题的模型
作者希望,任务型系统发展得越来越好以后,可以多多关注这个方向。
最后
数据集会发布在 https://github.com/budzianowski/multiwoz
知乎专栏
同名文章已发表在知乎专栏《机器学习算法与自然语言处理》
MultiWOZ再升级!|《MultiWOZ 2.2》ACL2020论文笔记


来必力目前使用QQ或微信登录会有bug,建议大家使用微博或其他社交账号登录。